
Trustworthy AI
The application of machine learning to support the processing of large datasets holds promise in many industries, including financial services. In fact, over 60% of financial services companies have embedded at least one Artificial Intelligence (AI) capability, ranging from how they communicate with their customers via virtual assistants, to automating key workflows, and even managing fraud and network security.
However, AI has been shown to have a “black box” issue, resulting in a lack of understanding about how systems can work to raise concerns about opacity, unfair discrimination, ethics and threats to individual privacy and autonomy. This lack of transparency can often include hidden biases.
AI Bias
Algorithm bias
This occurs when there’s a problem within the algorithm that performs the calculations that power the machine learning computations.
Sample bias
This happens when there’s a problem with the data used to train the machine learning model. In this type of bias, the data used is either not large enough or representative enough to teach the system. For example, in fraud detection it is common to receive 700,000 events per week where only one is fraudulent. Since the majority of the events are non-fraudulent, the system does not have enough examples to learn what fraud looks like, so it might assume all transactions are genuine. On the other hand, there are also cases where a vendor will share only what they consider as “risky” events or transactions (which is typically around 1% of the events). This creates the same bias problem for the training of machine learning models, since they do not have any samples of what a genuine event/transaction looks like to be able to differentiate between what is fraud and what is genuine.
Prejudice bias
In this case, the data used to train the system reflects existing prejudices, stereotypes and/or faulty societal assumptions, thereby introducing those same real-world biases into the machine learning itself. In financial services, an example would be special claims investigations. The special investigations team often receives requests for additional investigation from managers that have reviewed claims. Because the claims are judged as suspicious by the management team, the special investigators are more likely to assume it is fraudulent than not. When these claims are entered into an AI system with the label “fraud”, the prejudice that originated with special investigators is being propagated into the AI system that learns from these data what to recognize as fraud.
Measurement bias
This bias arises due to underlying problems with the accuracy of the data and how it was measured or assessed. Using pictures of happy workers to train a system meant to assess a workplace environment could be biased if the workers in the pictures knew they were being measured for happiness. Measurement bias can also occur at the data labeling stage due to inconsistent annotation. For example, if a team labels transactions as fraud, suspicious or genuine and someone labels a transaction as fraud but another person labels a similar one as suspicious, it will result in inconsistent labels and data.
Exclusion bias
This happens when an important data point is left out of the data being used –something that can happen if the modelers don’t recognize the data point as consequential. A relevant example here is new account fraud (i.e., cases where the account was created by a nefarious individual using a stolen or simulated identity or a new and genuine account that was taken over for the purpose of fraud). At the time of the new account opening, there are not enough data generated about the account because most modelers only start processing data after a predefined number of interactions has occurred. However, according to domain experts these first interactions that are not being immediately processed are among the most important. This simple lack of communication between domain experts and AI modelers can lead to unintentional exclusion and AI systems that are not able to detect new account fraud.
For financial institutions, the consequences of what are often unintentional biases in machine learning systems can be significant. Such biases could result in increased customer friction, lower customer service experiences, reduced sales and revenue, unfair or possibly illegal actions, and potential discrimination. Ask yourself, should organizations be able to use digital identity or social media to make judgments on your spending and likelihood to repay debts? Imagine being restricted from accessing essential goods and services just because of who you know, where you’ve been, what you’ve posted online, or even how many times you call your mother.
What is trustworthy AI?
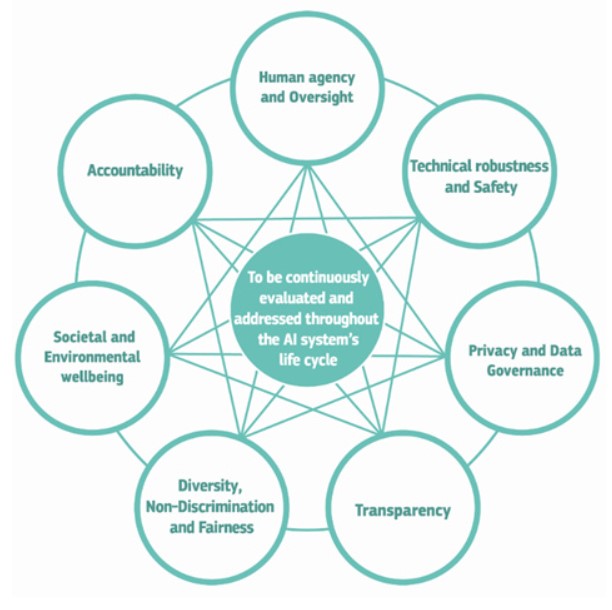
Trustworthy AI is a term used to describe AI that is lawful, ethically adherent, and technically robust. It is based on the idea that AI will reach its full potential when trust can be established in each stage of its lifecycle, from design to development, deployment and use.
There are several components needed to achieve AI accountability:
Privacy
Besides ensuring full privacy of the users as well as data privacy, there is also need for data governance access control mechanisms. These need to take into account the whole system lifecycle, from training to production which means personal data initially provided by the user, as well as the information generated about the user over the course of their interaction with the system.
Robustness
AI systems should be resilient and secure. They must be accurate, able to handle exceptions, perform well over time and be reproducible. Another important aspect is safeguards against adversarial threats and attacks. An AI attack could target the data, the model or the underlying infrastructure. In such attacks the data as well as system behavior can be changed, leading the system to make different or erroneous decisions, and even shut down completely. For AI systems to be robust they need to be developed with a preventative approach to risks aiming to minimize and prevent harm.
Explainability
Understanding is an important aspect in developing trust. It is important to understand how AI systems make decisions and which features were important to the decision making process for each decision. Explanations are necessary to enhance understanding and allow all involved stakeholders to make informed decisions.
Fairness
AI systems should be fair, unbiased, and accessible to all. Hidden biases in the AI pipeline could lead to discrimination and exclusion of underrepresented or vulnerable groups. Ensuring that AI systems are fair and include proper safeguards against bias and discrimination will lead to more equal treatment of all users and stakeholders.
Transparency: The data, systems and business models related to AI should be transparent. Humans should be aware when they are interacting with an AI system. Also, the capabilities and limitations of an AI system should be made clear to relevant stakeholders and potential users. Ultimately transparency will contribute to having more effective traceability, auditability, and accountability.
The potential risks in AI require the involvement of critical stakeholders across government, industry and academia to ensure effective regulation and standardization. Earlier this year, the European Commission presented the ethics guidelines for Trustworthy AI. They include principles to ensure that AI systems are fair, safe, transparent, and useful for end users. Also, in the US the National Institute for Standards and Technology (NIST) is working on developing standards and tools to ensure AI is trustworthy.
The publication of this article has been extracted and freely adapted from OneSpan Blog – Author Ismini Psychoula